Skład podręcznika akademickiego w LaTeX — od manuskryptu do druku
Kompletny przewodnik po procesie tworzenia podręcznika w LaTeX-u. Struktura książki, rozdziały, indeksy, glosariusze, spisy treści, bibliografie, ilustracje, środowiska dydaktyczne i przygotowanie PDF-a do druku. Dlaczego LaTeX jest standardem wydawnictw naukowych.
Dostajesz od autora 400 stron manuskryptu w Wordzie. Dwanaście rozdziałów, 200 wzorów, 80 rysunków, 35-stronicowa bibliografia i wymóg: „indeks rzeczowy na końcu”. Otwierasz plik — a tam trzy różne style nagłówków, ręcznie wpisane numery rozdziałów, bibliografia sformatowana „na oko” i wzory wstawione jako screenshoty z tablicy. Znasz ten scenariusz. My też — i dlatego każdy podręcznik, który składamy, robimy w LaTeX-u. Ten artykuł pokazuje cały proces: od surowego tekstu autora do gotowego PDF-a w jakości drukarskiej, z każdym mechanizmem opisanym tak, żebyś mógł go użyć od razu. Jeśli dopiero zaczynasz swoją przygodę z tym narzędziem, sprawdź najpierw jak zacząć ze składem w LaTeX.
Dlaczego LaTeX jest standardem wydawnictw naukowych
To nie jest kwestia mody ani przyzwyczajenia. LaTeX dominuje w wydawnictwach akademickich z powodów czysto technicznych, które przy skali podręcznika stają się krytyczne.
Springer, Cambridge University Press, MIT Press, Oxford University Press, Elsevier, Princeton University Press — wszystkie te wydawnictwa dostarczają autorom własne klasy LaTeX-owe (pliki .cls) i makra do przygotowywania manuskryptów. MIT Press na swojej stronie pisze wprost: „We strongly recommend their use”. Cambridge University Press w swoim przewodniku dla autorów zaleca pakiet MakeIndex do tworzenia indeksów i BibTeX do bibliografii — jeszcze na etapie pisania, nie składu.
Powody są konkretne. Po pierwsze, stabilność na dużych dokumentach — plik .tex to czysty tekst, który nie akumuluje ukrytych metadanych i nie ulega uszkodzeniu. 500-stronicowy podręcznik kompiluje się tak samo niezawodnie jak 5-stronicowa notatka. Po drugie, automatyzacja — spis treści, numeracja rozdziałów, wzorów, tabel, rysunków, cross-referencje, indeks i bibliografia generują się automatycznie z jednego źródła. Po trzecie, powtarzalność — ten sam plik .tex skompilowany za 10 lat da identyczny PDF. Po czwarte, jakość typograficzna — algorytm Knutha-Plassa, mikrotypografia, precyzyjny skład wzorów matematycznych — to mechanizmy, które opisaliśmy szczegółowo w artykule LaTeX vs Word.
Word przy podręczniku akademickim nie jest „trudniejszy”. On jest niewystarczający — strukturalnie nie radzi sobie z zadaniami, które w LaTeX-u są trywialne.
Architektura projektu — jak zorganizować 400 stron
Podręcznik akademicki to nie jeden plik. To projekt składający się z dziesiątek plików .tex, plików graficznych, bazy bibliograficznej i plików konfiguracyjnych. Dobrze zorganizowana struktura katalogów to fundament, bez którego praca nad dużym dokumentem zamienia się w chaos.
Oto sprawdzona struktura, której używamy w produkcji:
podrecznik/
├── main.tex % plik główny — szkielet książki
├── preambula.tex % wszystkie pakiety i konfiguracja
├── front/
│ ├── tytulowa.tex % strona tytułowa
│ ├── dedykacja.tex % opcjonalna dedykacja
│ ├── przedmowa.tex % przedmowa autora
│ └── symbole.tex % spis oznaczeń i symboli
├── rozdzialy/
│ ├── 01-wstep.tex
│ ├── 02-podstawy.tex
│ ├── 03-metody.tex
│ ├── ...
│ └── 12-podsumowanie.tex
├── dodatki/
│ ├── A-dowody.tex
│ ├── B-tablice.tex
│ └── C-rozwiazania.tex
├── bib/
│ └── bibliografia.bib % baza źródeł BibTeX
├── img/
│ ├── roz01/ % grafiki pogrupowane rozdziałami
│ ├── roz02/
│ └── ...
└── sty/
└── podrecznik.sty % własny pakiet ze stylamiKluczowa zasada: jeden rozdział = jeden plik. Plik główny main.tex jest tylko szkieletem, który łączy wszystko w całość za pomocą komend \include{}.
Plik główny — szkielet książki
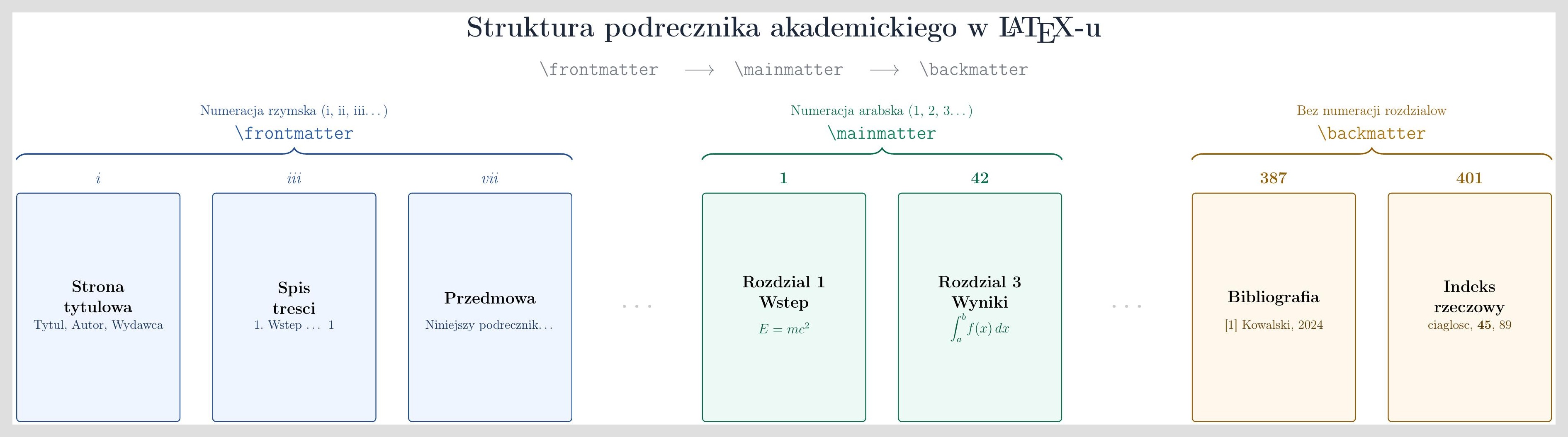
Plik main.tex podręcznika wygląda zupełnie inaczej niż plik artykułu. Klasa book (lub jej odpowiednik z rodziny KOMA-Script — scrbook) wprowadza trójdzielną strukturę, której nie mają klasy article ani report: frontmatter, mainmatter i backmatter.
\documentclass[12pt, a4paper, twoside, openright]{book}
\input{preambula} % ładuje pakiety i konfigurację
\begin{document}
% ── Frontmatter ────────────────────────
\frontmatter % numeracja rzymska (i, ii, iii...)
% rozdziały nienumerowane
\include{front/tytulowa}
\include{front/dedykacja}
\include{front/przedmowa}
\tableofcontents
\listoffigures
\listoftables
\include{front/symbole}
% ── Mainmatter ─────────────────────────
\mainmatter % numeracja arabska (1, 2, 3...)
% rozdziały numerowane
\include{rozdzialy/01-wstep}
\include{rozdzialy/02-podstawy}
\include{rozdzialy/03-metody}
% ... kolejne rozdziały ...
\include{rozdzialy/12-podsumowanie}
% ── Backmatter ─────────────────────────
\backmatter % numeracja ciągła, rozdziały
% nienumerowane
\appendix
\include{dodatki/A-dowody}
\include{dodatki/B-tablice}
\include{dodatki/C-rozwiazania}
\printbibliography[heading=bibintoc]
\printindex
\end{document}Trzy komendy — \frontmatter, \mainmatter, \backmatter — robią za kulisami więcej, niż się wydaje:
\frontmatter— przełącza numerację stron na cyfry rzymskie (i, ii, iii…), wyłącza numerację rozdziałów, ale zachowuje ich tytuły w spisie treści. Tutaj trafia wszystko, co poprzedza właściwą treść: strona tytułowa, dedykacja, przedmowa, spisy.\mainmatter— resetuje licznik stron, przełącza na cyfry arabskie (1, 2, 3…) i włącza numerację rozdziałów. To rdzeń podręcznika.\backmatter— kontynuuje bieżącą numerację stron, ale ponownie wyłącza numerację rozdziałów. Tutaj trafiają dodatki, bibliografia i indeks.
Opcje klasy book w pierwszej linii też mają znaczenie. twoside aktywuje układ dwustronny z różnymi marginesami na stronach parzystych i nieparzystych (margines wewnętrzny — przy grzbiecie — jest szerszy niż zewnętrzny). openright wymusza rozpoczynanie każdego rozdziału na stronie nieparzystej (prawej) — standard w profesjonalnych podręcznikach.
Preambula podręcznika — pakiety i konfiguracja
Preambula podręcznika jest znacznie obszerniejsza niż preambula artykułu. Wydzielamy ją do osobnego pliku preambula.tex, żeby plik główny pozostał czytelny. Oto konfiguracja, której używamy w produkcji:
% ── Kodowanie i język ──────────────────
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
\usepackage[polish]{babel}
\usepackage{lmodern}
% ── Układ strony ───────────────────────
\usepackage[
top=2.5cm,
bottom=2.5cm,
inner=3cm, % margines przy grzbiecie (szerszy)
outer=2cm, % margines zewnętrzny
bindingoffset=5mm % dodatkowy offset na oprawę
]{geometry}
% ── Typografia ─────────────────────────
\usepackage{microtype}
\usepackage{setspace}
\onehalfspacing % interlinia 1.5 (standard wydawniczy)
% ── Nagłówki i stopki ─────────────────
\usepackage{fancyhdr}
\pagestyle{fancy}
\fancyhf{}
\fancyhead[LE]{\thepage\quad\textsc{\nouppercase{\leftmark}}}
\fancyhead[RO]{\textsc{\nouppercase{\rightmark}}\quad\thepage}
\renewcommand{\headrulewidth}{0.4pt}
% ── Matematyka ─────────────────────────
\usepackage{amsmath, amssymb, amsthm}
\usepackage{mathtools}
% ── Ilustracje i tabele ───────────────
\usepackage{graphicx}
\graphicspath{{img/}}
\usepackage{booktabs}
\usepackage{float}
\usepackage{subcaption} % podrysunki (a), (b),